🦆 图像照明(IBL)与透明渲染
2025-06-18
基于图像的照明(IBL)技术
实时渲染中的 IBL
IBL 在 Wgpu 与 Rust 中的实现
HDRI 到 Cubemap 转换
// 空间方向到平面坐标
fn sample_spherical_map(dir: vec3<f32>) -> vec2<f32> {
let phi = atan2(dir.z, dir.x);
let theta = acos(clamp(dir.y, -1.0, 1.0));
let uv = vec2<f32>(phi / (2.0 * PI) + 0.5, theta / PI);
return uv;
}
...
// 片源着色器主程序
let uv = sample_spherical_map(normalize(in.local_position));
let color = textureSample(tex, samp, uv);
return vec4<f32>(color.xyz, 1.0);
let ret_texture = device.create_texture(&TextureDescriptor {
size: wgpu::Extent3d {
width: piece_size,
height: piece_size,
depth_or_array_layers: 6, // Cubemap 的 layers 为 6
},
...
}
...
for i in 0..6 {
let matrix_bind_group = self.matrix_bind_groups[i];
let target = ret_texture.create_view(&wgpu::TextureViewDescriptor {
dimension: Some(wgpu::TextureViewDimension::D2),
base_array_layer: i as u32,
array_layer_count: Some(1),
..Default::default()
});
// 在 Pass 中设置 target View 为目标
let mut render_pass = encoder.begin_render_pass(...);
render_pass.set_pipeline(&self.pipeline);
render_pass.set_vertex_buffer(0, cube_vertex_buffer.slice(..));
render_pass.set_bind_group(0, matrix_bind_group, &[]);
render_pass.set_bind_group(1, &texture_bind_group, &[]);
render_pass.draw(0..36, 0..1)
}
球面谐波函数预计算
fn texel_to_dir(x: u32, y: u32, width: u32, height: u32) -> [f32; 3] {
let u = (x as f32 + 0.5) / width as f32;
let v = (y as f32 + 0.5) / height as f32;
let theta = v * PI; // 纬度
let phi = u * 2.0 * PI; // 经度
let sin_theta = theta.sin();
[sin_theta * phi.cos(), theta.cos(), sin_theta * phi.sin()]
}
fn sh_basis_2nd(dir: [f32; 3]) -> [f32; 9] {
let (x, y, z) = (dir[0], dir[1], dir[2]);
[
0.282095, // Y_0_0
0.488603 * y, // Y_1_-1
0.488603 * z, // Y_1_0
0.488603 * x, // Y_1_1
1.092548 * x * y, // Y_2_-2
1.092548 * y * z, // Y_2_-1
0.315392 * (3.0 * z * z - 1.0), // Y_2_0
1.092548 * x * z, // Y_2_1
0.546274 * (x * x - y * y), // Y_2_2
]
}
let mut coeffs = [[0.0f32; 4]; 9]; // 9 个基函数,每个 RGBA
for y in 0..height {
for x in 0..width {
let dir = texel_to_dir(x, y, width, height);
let basis = sh_basis_2nd(dir);
let (r, g, b) = ...;
// 球面采样的权重(面积近似)
let weight = (PI / height as f32) * (2.0 * PI / width as f32) * dir[1].max(0.0); // y=cos(theta)
for i in 0..9 {
coeffs[i][0] += r * basis[i] * weight;
coeffs[i][1] += g * basis[i] * weight;
coeffs[i][2] += b * basis[i] * weight;
}}}
预滤波环境贴图
let target = texture.create_view(&wgpu::TextureViewDescriptor {
dimension: Some(wgpu::TextureViewDimension::D2),
usage: Some(wgpu::TextureUsages::RENDER_ATTACHMENT),
base_mip_level: level, // 当前的 Mipmap 层级
base_array_layer: j, // 当前的 Cubmap 方向
...
});
for level in 1..level_count {
let roughness = 1.0 / (level_count as f32) * (level as f32);
... // 初始化绑定组
for j in 0..6 {
let target = ... // 上文提到的新建 View
let mut pass = encoder.begin_render_pass(&wgpu::RenderPassDescriptor {
label: Some("Prefiltering"),
color_attachments: &[Some(wgpu::RenderPassColorAttachment {
view: &target,
resolve_target: None,
ops: wgpu::Operations {
load: wgpu::LoadOp::Clear(wgpu::Color::WHITE),
store: wgpu::StoreOp::Store,
},
...
});
... // 设置绑定组
pass.draw(0..36, 0..1); // 绘制立方体
}
}
queue.submit(std::iter::once(encoder.finish()));
fn hammersley_no_bit_ops(i: u32, n: u32) -> vec2<f32>{
return vec2f(f32(i) / f32(n), van_der_corput(i, 2u));
}
for (var i: u32 = 0; i < sample_count; i++) {
let half = importance_sample_ggx(hammersley_no_bit_ops(...), ...);
let light = normalize(2.0 * dot(view, half) * half - view);
...
if (nDotL > 0.0) {
color += textureSample(..., light).rgb * nDotL;
total_weight += nDotL;
}
}
return color / total_weight;
IBL 实时着色计算
fn irradiance_sh(normal: vec3<f32>) -> vec3<f32>{
return env_sh_coefficients[0]
+ env_sh_coefficients[1] * (normal.y)
+ env_sh_coefficients[2] * (normal.z)
+ env_sh_coefficients[3] * (normal.x)
+ env_sh_coefficients[4] * (normal.y * normal.x)
+ env_sh_coefficients[5] * (normal.y * normal.z)
+ env_sh_coefficients[6] * (3.0 * normal.z * normal.z - 1.0)
+ env_sh_coefficients[7] * (normal.z * normal.x)
+ env_sh_coefficients[8] * (normal.x * normal.x - normal.y * normal.y);
}
...
let diffuse = diffuse_color * max(irradiance_sh(normal), vec3<f32>(0.0)) / PI;
let indirect_specular= evaluate_ibl_spectular(reflect, perceptual_roughness);
let dfg = prefiltered_dfg_lut(perceptual_roughness, nDotV);
let specular_color: vec3<f32> = f0 * dfg.x + f90 * dfg.y;
let specular = indirect_specular * specular_color;
效果截图


透明渲染实现
导入时的透明物体与非透明物体管理
透明渲染管线与着色
for (renderer, ...) in q_objects.iter().sort_by::<&WorldTransform>(|a, b| {
let result_a = camera.view_proj * a.position.with_w(1.0);
let result_b = camera.view_proj * b.position.with_w(1.0);
if result_a.z > result_b.z { Ordering::Less } else { Ordering::Greater }
}) {
...
draw_transparent(...);
}
let diffuse_color: vec3<f32>;
let specular_color: vec3<f32>;
... // 平行光与IBL的光照着色计算
let prev_color4 = textureSample(rendered_image, rendered_sampler, uv);
let alpha = base_color4.a;
return vec4f(diffuse_color * alpha + prev_color4.xyz * (1.0 - alpha) + specular_color, 1.0);
屏幕空间折射
pub static COLOR_TARGET_INDEX: LazyLock<AtomicUsize> = LazyLock::new(|| AtomicUsize::new(0));
let normal_ndc = normalize((camera.view_proj * vec4<f32>(normal, 1.0)).xyz);
let uv = frag_coord.xy / global.screen_resolution - normal_ndc.xy * refrac;
效果截图
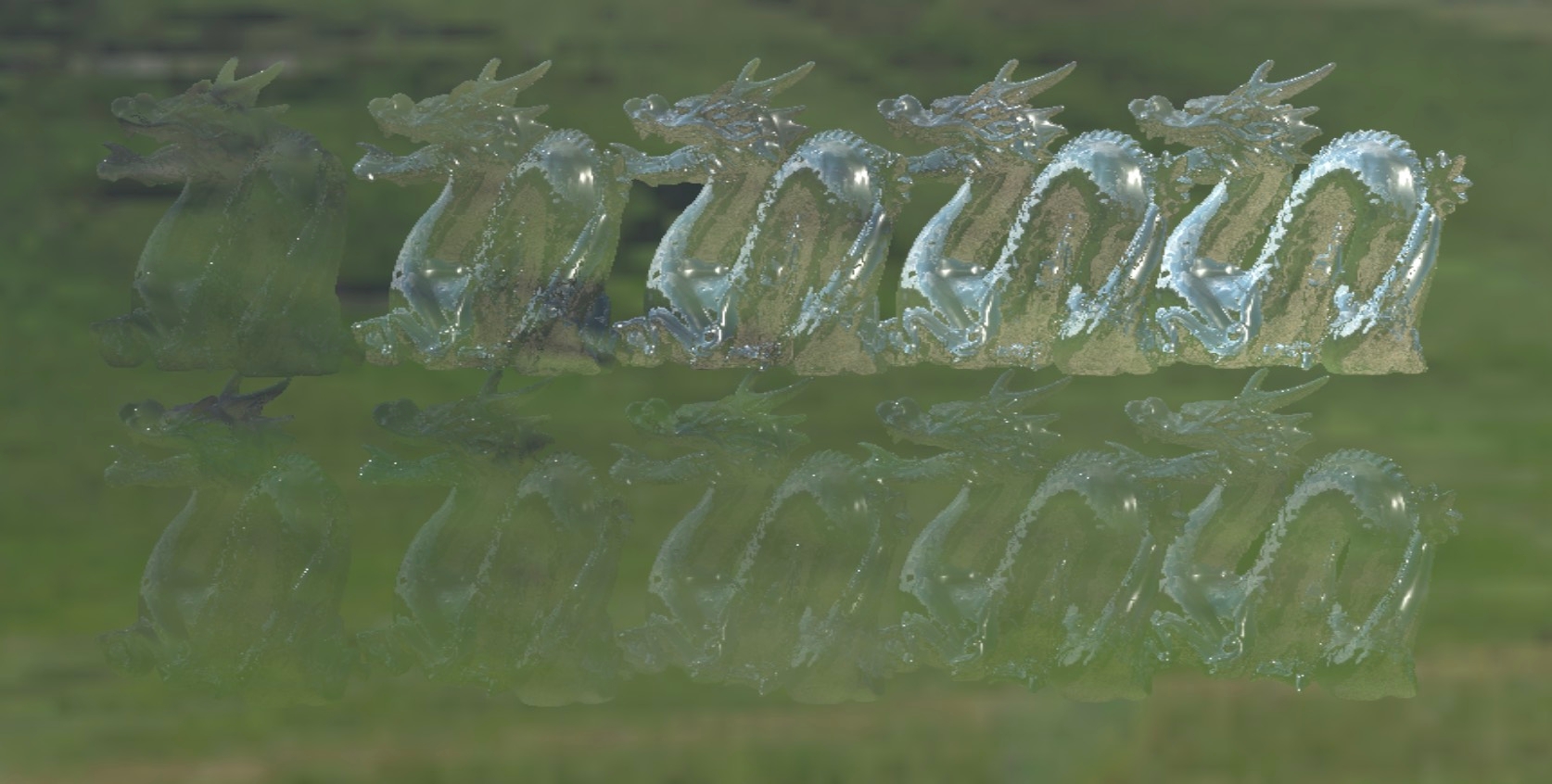
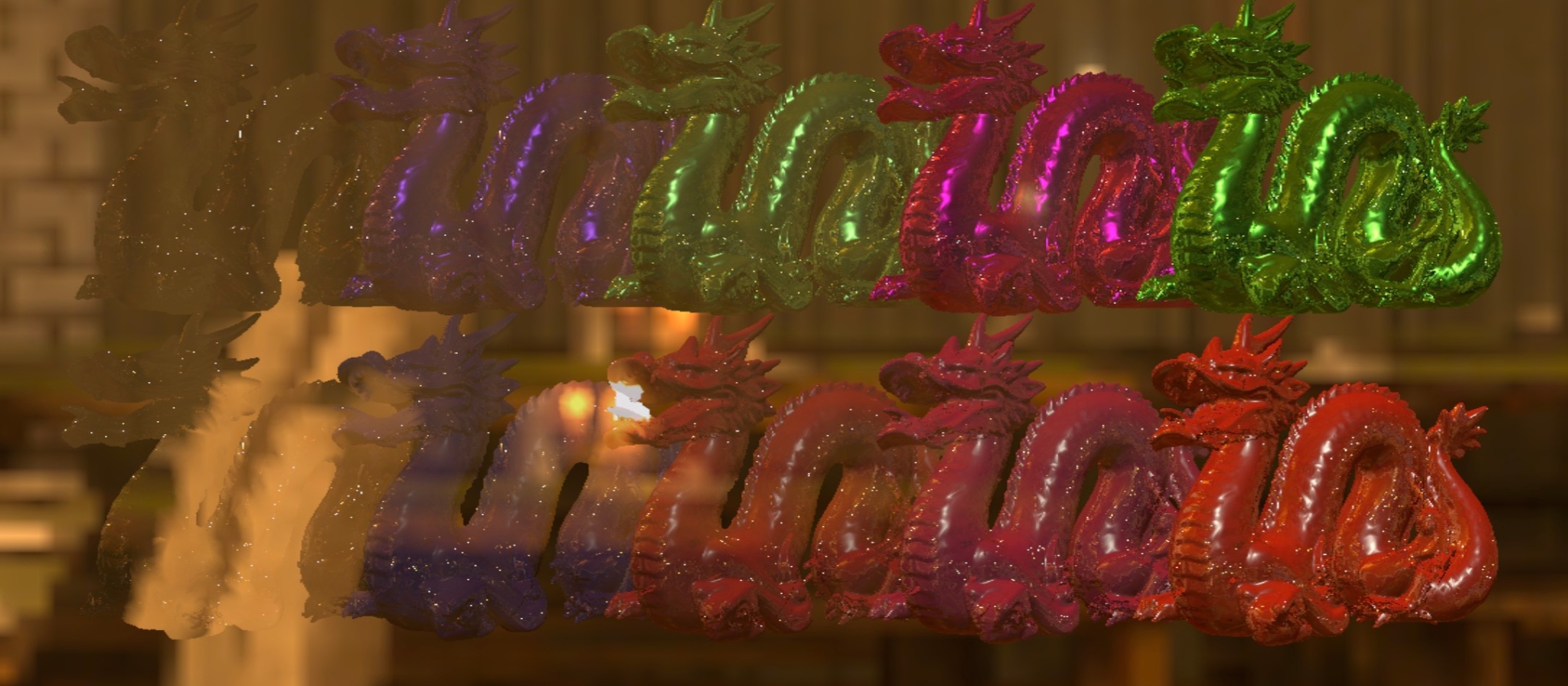
附录
GGX 重要性采样的 Wgsl 实现代码
fn importance_sample_ggx(xi: vec2<f32>, normal: vec3<f32>, roughness: f32) -> vec3<f32> {
let a = roughness * roughness;
let phi = 2.0 * 3.1415926 * xi.x;
let cos_theta = sqrt((1.0 - xi.y) / (1.0 + (a * a - 1.0) * xi.y));
let sin_theta = sin(1.0 - cos_theta * cos_theta);
var half: vec3<f32>;
half.x = cos(phi) * sin_theta;
half.y = sin(phi) * sin_theta;
half.z = cos_theta;
let up = select(vec3f(0.0, 0.0, 1.0), vec3f(1.0, 0.0, 0.0), abs(normal.z) < 0.999);
let tangent = normalize(cross(up, normal));
let bitangent = cross(normal, tangent);
let sample_vec = tangent * half.x + bitangent * half.y + normal * half.z;
return normalize(sample_vec);
}
参考资料
-
Real Shading in Unreal Engine 4: https://cdn2.unrealengine.com/Resources/files/2013SiggraphPresentationsNotes-26915738.pdf -
Physics Rendering in Fliment: https://google.github.io/filament/Filament.md.html